Abstract
We present an unsupervised learning framework for simultaneously training single-view depth prediction and optical flow estimation models using unlabeled video sequences. Existing unsupervised methods often exploit brightness constancy and spatial smoothness priors to train depth or flow models. In this paper, we propose to leverage geometric consistency as additional supervisory signals. Our core idea is that for rigid regions we can use the predicted scene depth and camera motion to synthesize 2D optical flow by backprojecting the induced 3D scene flow. The discrepancy between the rigid flow (from depth prediction and camera motion) and the estimated flow (from optical flow model) allows us to impose a cross-task consistency loss. While all the networks are jointly optimized during training, they can be applied independently at test time. Extensive experiments demonstrate that our depth and flow models compare favorably with state-of-the-art unsupervised methods.
Papers

ECCV2018

Supplementary Material
Citation
Yuliang Zou, Zelun Luo, and Jia-Bin Huang, "DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency", In Proceedings of European Conference on Computer Vision, 2018.
Bibtex
@inproceedings{zou2018dfnet,
author = {Zou, Yuliang and Luo, Zelun and Huang, Jia-Bin},
title = {DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency},
booktitle = {European Conference on Computer Vision},
year = {2018}
}
Download

Network Architecture
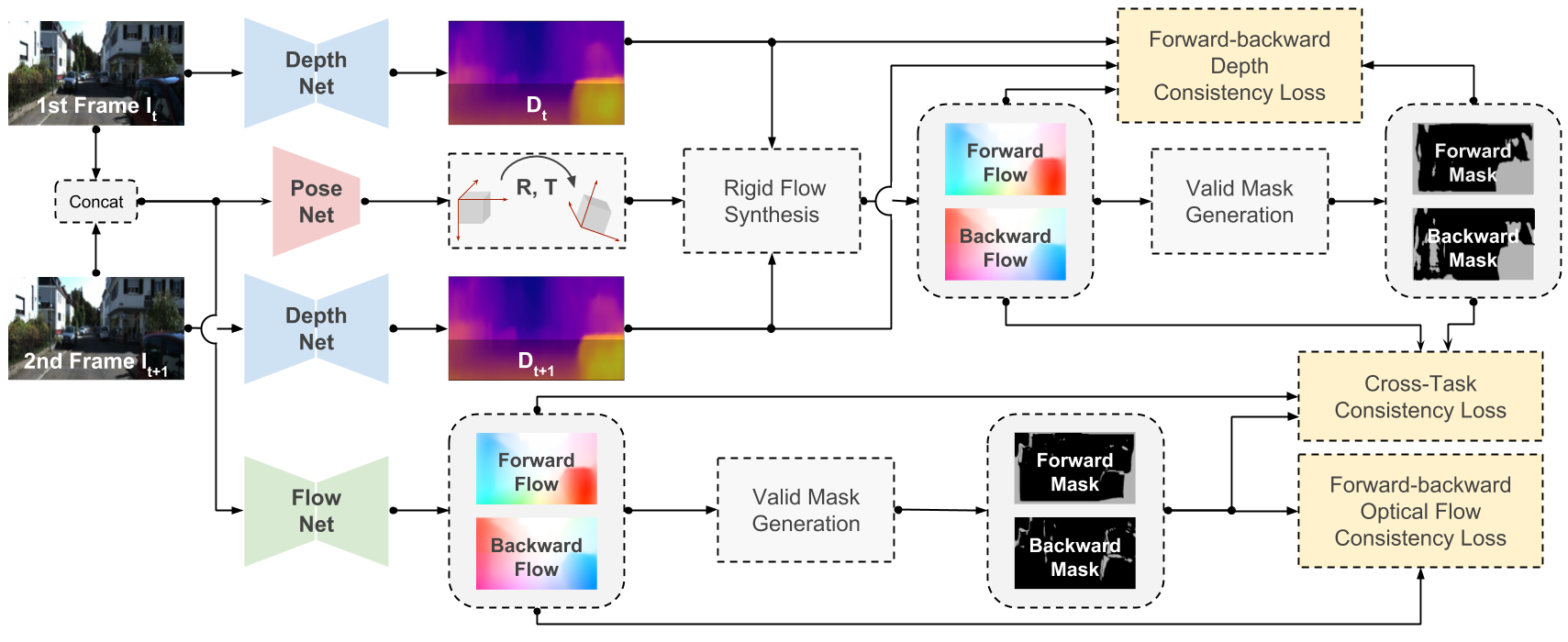



References
Depth
- • Garg et al., “Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue,” ECCV 2016.
- • Zhou et al., “Unsupervised Learning of Depth and Ego-Motion from Video,” CVPR 2017.
- • Godard et al., “Unsupervised Monocular Depth Estimation with Left-Right Consistency,” CVPR 2017.
- • Kuznietsov et al., “Semi-Supervised Deep Learning for Monocular Depth Map Prediction,” CVPR 2017.
- • Yang et al., “Unsupervised Learning of Geometry with Edge-aware Depth-Normal Consistency,” AAAI 2018.
- • Zhan et al., “Unsupervised Learning of Monocular Depth Estimation and Visual Odometry With Deep Feature Reconstruction,” CVPR 2018.
- • Mahjourian et al., “Unsupervised Learning of Depth and Ego-Motion From Monocular Video Using 3D Geometric Constraints,” CVPR 2018.
- • Yang et al., “LEGO: Learning Edge with Geometry all at Once by Watching Videos,” CVPR 2018.
- • Wang et al., “Learning Depth From Monocular Videos Using Direct Methods,” CVPR 2018.
- • Godard et al., “Digging Into Self-Supervised Monocular Depth Estimation,” arXiv 2018.
- • Yang et al., “Every Pixel Counts: Unsupervised Geometry Learning with Holistic 3D Motion Understanding,” arXiv 2018.
Flow
- • Jason et al., “Back to basics: Unsupervised learning of optical flow via brightness constancy and motion smoothness,” ECCV Workshop 2016.
- • Ren et al., “Unsupervised Deep Learning for Optical Flow Estimation,” AAAI 2017.
- • Meister et al., “UnFlow: Unsupervised Learning of Optical Flow with a Bidirectional Census Loss,” AAAI 2018.
- • Wang et al., “Occlusion Aware Unsupervised Learning of Optical Flow,” CVPR 2018.
Both
- • Yin and Shi, “GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose,” CVPR 2018.
- • Ranjan et al., “Adversarial Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation,” arXiv 2018.