Abstract
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs.
Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation.
Overview
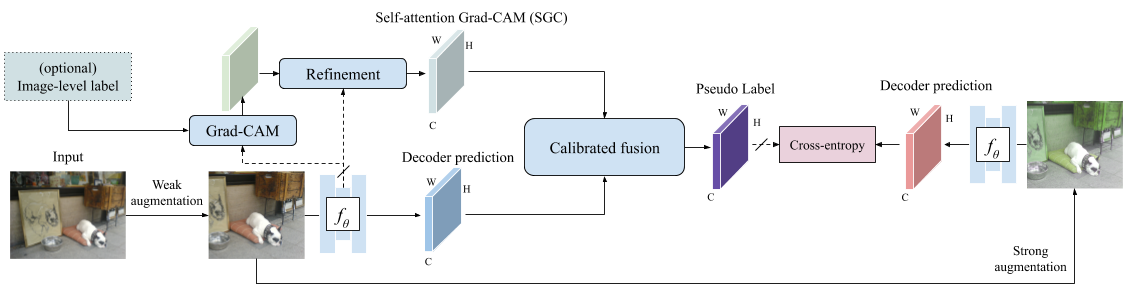
Papers

arXiv
Citation
Yuliang Zou, Zizhao Zhang, Han Zhang, Chun-Liang Li, Xiao Bian, Jia-Bin Huang, and Tomas Pfister, "PseudoSeg: Designing Pseudo Labels for Semantic Segmentation", In Proceedings of International Conference on Learning Representations, 2021.
Bibtex
@inproceedings{zou2021pseudoseg,
title={PseudoSeg: Designing Pseudo Labels for Semantic Segmentation},
author={Zou, Yuliang and Zhang, Zizhao and Zhang, Han and Li, Chun-Liang and Bian, Xiao and Huang, Jia-Bin and Pfister, Tomas},
booktitle={International Conference on Learning Representations},
year={2021}
}
